LION COMMUNITY USAGE CASE
Credit approval for bank customers.
This is an exercise associated with the AMLbook (see reference) and the course "Learning from Data" by Caltech Professor Yaser Abu-Mostafa.
A typical financial problem is to investigate which bank customers are reliable enough to give them credit. Banks have their databases of previous customers and previous credit history, which can be mined to extract classification systems, in an automated manner. This classification can be made through a Neural Network, a model capable of extracting rules associating characteristics of a customer to a prediction of customer reliability.
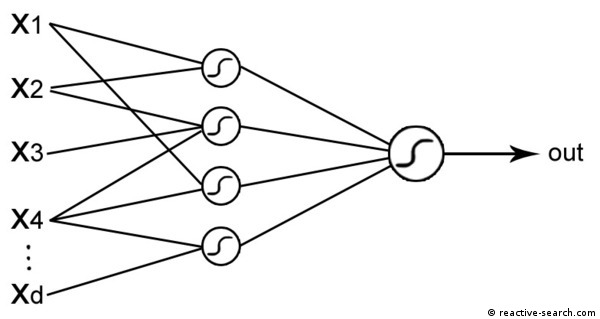
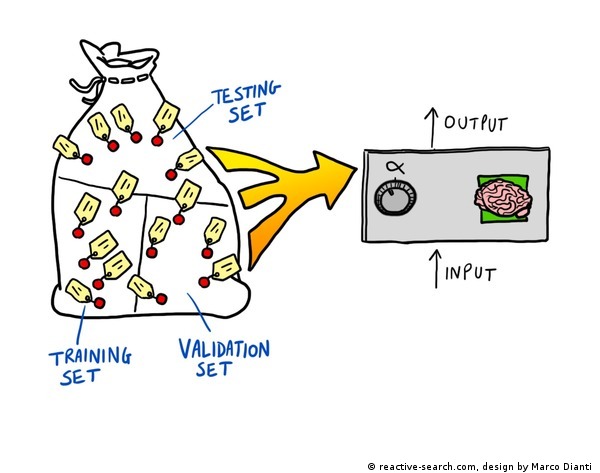
We load into LIONoso a data set of customers, classified as risky (1) or not risky (0) through the attribute "Evaluation"; we select the seven most informative input variables (see below); we then train a neural network on these data, and finally perform a predictive analysis on a test set which has not been used during training. The appropriate way to proceed is:
- Train the neural network on the TRAINING set
- Define the "optimal" network and decide to stop training by using the VALIDATION set
- Assess prediction error by using the TEST set
Data:
(see cited reference for more details)- Status of existing checking account
- Duration in month
- Credit history
- Credit amount
- Savings account/bonds
- Housing: "rent", "own", "for free"
- Foreign worker: "yes" or "no"
- Evaluation: if there is credit risk or not
Training of a Neural Network
We randomly divide our data set into two subset: a training set consisting of 666 records and a test set consisting of 334 records.
After training the Neural Network, we test it on the test data set, in order to measure the accuracy of the model.
The configuration of LIONoso's workbench is shown below.

The accuracy is given by the ratio between the number of records correctly classified and the total number of records used for testing (in our case, 334). The learning task is far from trivial, data are very noisy, and only a subset of the inputs are informative (see the above list for our suggestion). We tried several experiments with a different number of hidden layer neurons (by using a 0-1 sigmoid in the middle and output layer, and input data normalization). For the considered architecture, the performance is rather stable with respect to the number of hidden neurons.

To visualize the difference between target and obtained (predicted) outputs, a bar chart with subclasses can be used to visualize how the Evaluation-target variable is related to the Evaluation value. The Evaluation value is obtained by passing the test data through the trained neural network. The above figure illustrates the distribution, together with the evolution of the training and validation (test) mean squared errors during the training history.
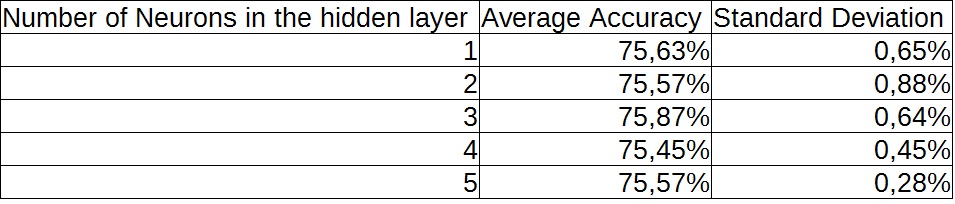
The accuracy values are comparable with the results given in the article "Combining feature selection and neural networks for solving classification problems", which describes a similar experiment on the same data set. Actually the accuracy is slightly better. More complex predictions may consider different costs for errors of different kinds, please contact us if you are interested in the details of this usage case.
Download the LIONoso-ready file: credit.lion
Download additional training and test files:
- credit-train.csv, credit-test.csv (original credit approval data)
P. O'Dea, J. Griffith, and C. O'Riordan, "Combining feature selection and neural networks for solving classification problems" , in Proc. 12th Irish Conf. Artificial Intell. Cognitive Sci., Sep. 2001, pp. 157-166.
Data collected from UCI Machine Learning Repository (http://archive.ics.uci.edu/ml/datasets/Statlog+(German+Credit+Data) ), Source: Professor Dr. Hans Hofmann, Institut fuer Statistik und Oekonometrie, Universitaet Hamburg.
The neural network images are from the book: The LION way
Roberto Battiti and Mauro Brunato. LIONlab, University of Trento, Feb 2014.
[AMLbook] Learning from data
Yaser S. Abu-Mostafa, Malik Magdon-Ismail, Hsuan-Tien Lin. 2012.