LION COMMUNITY USAGE CASE
Logistic regression for predicting heart diseases.
This is an exercise associated with the
CaltechX: CS1156x Learning From Data (introductory Machine Learning course)
by Caltech Professor Yaser Abu-Mostafa.
In statistics, logistic regression is used for predicting the outcome of a categorical variable based on predictor variables. With reference to the considered usage case, one starts from data about patients which can have a heart disease (disease yes or no is the categorical output variable) and wants to predict the probability that a new patient has the heart disease. A logistic function is used to transform the output of a linear predictor to obtain a value between zero and one, which can be interpreted as a probability.
The best values for the weights of the linear transformation are determined by maximizing the probability of getting the output values actually obtained on the given labeled examples (probabilities of individual independent cases are multiplied).
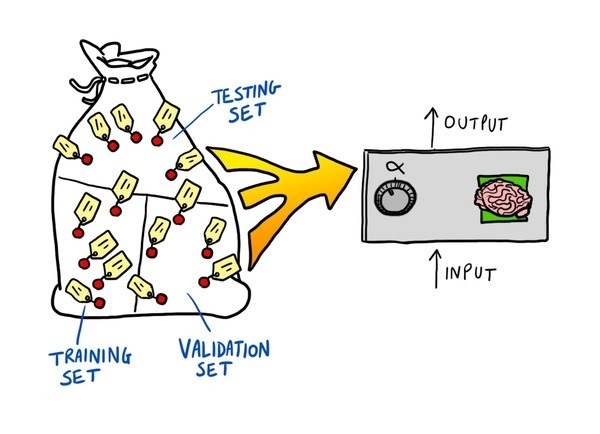
We load into LIONoso a data set of patients, classified as having (1) or not having (0) the heart disease. We then train a logistic predictor on these data, by gradient descent, and finally perform a predictive analysis on a test set which has not been used during training. The appropriate way to proceed is:
- Train the logistic predictor on the TRAINING set
- Use a validation set to determine the best parameters for training (training rate and number of iterations)
- Obtain predicted probabilities (and classification) by using the TESTING set
Data:
(see cited UCI reference for more details)- age
- sex
- cp: chest pain type.
- trestbps: resting blood pressure (in mm Hg on admission to the hospital)
- chol: serum cholestoral in mg/dl
- fbs: (fasting blood sugar > 120 mg/dl) (1 = true; 0 = false)
- restecg: resting electrocardiographic results
- thalach: maximum heart rate achieved
- exang: exercise induced angina (1 = yes; 0 = no)
- oldpeak = ST depression induced by exercise relative to rest
- slope: the slope of the peak exercise ST segment
- ca: number of major vessels (0-3) colored by flourosopy
- thal: 3 = normal; 6 = fixed defect; 7 = reversable defect
- heartdisease::category|0|1 (the predicted attribute, the type is declared to be a category, with the two possible values).
Training a logistic predictor
We randomly divide the "Cleveland" data set into two subset: a training set consisting of 155 records and a test set consisting of 148 records.
After training the logistic regressor, we test it on the test data set, in order to measure the accuracy of the model.
The configuration of LIONoso's workbench is shown below.

The accuracy is given by the ratio between the number of records correctly
classified and the total number of records used for testing.
The obtained accuracy values are within 80% to 85% depending on the detailed split and training
parameters, in agreement with accuracy obtained by various researchers using the same data.
The confusion matrix showing errors of different kinds (false positives and false negatives)
is shown with the bar chart with subclasses below.
Please contact us if you are interested in the details of this usage case.

Download the LIONoso-ready file: logit.lion
Download additional training and test files:
- logit-train.csv, logit-test.csv (original heart disease prediction data)
Data collected from UCI Machine Learning Repository, Heart Disease data (http://archive.ics.uci.edu/ml/datasets/Heart+Disease ),
[AMLbook] Learning from data
Yaser S. Abu-Mostafa, Malik Magdon-Ismail, Hsuan-Tien Lin. 2012.